|
|
Купить решения «Лаборатории Касперского»
в интернет-магазине Kaspersky-Security.ru |
Как искусственный интеллект изменит нашу жизнь | Блог Касперского
Как подготовиться к жизни в дивном новом мире с ChatGPT, Midjourney, DALL-E 2 и другими решениями будущего на базе искусственного интеллекта
Дисклеймер: мнение автора не обязательно совпадает с официальной позицией «Лаборатории Касперского».
Искусственный интеллект однозначно стал главной темой мира технологий в 2022 году. Скажу откровенно: я всегда считал неоправданным ажиотаж вокруг применения ИИ в кибербезопасности. Машинное обучение может приносить реальную пользу, но в мире информационной безопасности упоминания ИИ встречались лишь в продуктовых презентациях, вызывающих острое чувство неловкости. Поэтому фразы вроде «решение на базе ИИ» выглядели для меня как элегантный способ сказать: «У нас нет ни базы знаний, ни телеметрии, но мы разработали пару эвристических алгоритмов». И я по-прежнему убежден, что более чем в 95% случаев в самих решениях собственно искусственного интеллекта почти и не было. Но, пока маркетологи клеили стикеры «ИИ» на любой продукт, в работе которого использовался метод k-средних, технологии настоящего искусственного интеллекта продвигались вперед.
Эту истину я осознал, когда впервые попробовал в деле DALL-E 2 (и вскоре после этого — Midjourney). Оба проекта генерируют изображения по текстовым описаниям и уже вызвали большой переполох в мире искусства.

Это изображение сгенерировано нейросетью Midjourney по запросу «Слава нашим новым ИИ-повелителям» (оригинальный запрос на английском языке: «All hail our new AI overlords»)
Затем, в декабре прошлого года, весь мир покорил ChatGPT. Говоря простыми словами, это чат-бот. Полагаю, многие уже попробовали его в действии, а если нет — настоятельно рекомендую это сделать (главное — не перепутать его с вирусом). ChatGPT значительно превосходит предыдущие подобные проекты. Стоит поговорить с ним, чтобы на собственном опыте убедиться, что будущее наступает.

ChatGPT говорит сам за себя
Как говорил сэр Артур Кларк, «любая достаточно развитая технология неотличима от магии». Мне нравится ощущение чуда, которым технологии порой наполняют нашу жизнь. Но, к сожалению, иногда оно мешает нам осознать, чем грозит очередной научный прорыв и где проходят границы возможного. Поэтому я считаю, что стоит потратить время и хорошенько разобраться в плюсах, минусах и подводных камнях новых технологий. Этим мы и займемся.
Языковые модели
Давайте начнем с ChatGPT — это на данный момент крупнейшая (из доступных широкой публике) языковая модель. Как и в случае со многими другими масштабными проектами машинного обучения, никто до конца не знает, как она работает (даже ее создатели OpenAI). То есть мы знаем, как модель была создана, но она слишком сложна, чтобы понять ее в строгом смысле этого слова. ChatGPT содержит более 175 миллиардов параметров. Чтобы осознать, о чем речь, представьте гигантскую машину со 175 миллиардами ручек, которые можно вращать под разными углами. Текстовый запрос, отправленный в ChatGPT, ставит каждую из этих ручек в то или иное положение. И машина, в зависимости от этих положений, выдает некий результат — в нашем случае текст. Кроме того, в систему добавлен элемент случайности, чтобы на один и тот же вопрос не всегда получался один и тот же ответ (но это можно скорректировать).
Поэтому мы воспринимаем подобные модели как черные ящики: никто не понимает, что происходит внутри них. Вероятно, даже если человек потратит на изучение такой машины всю свою жизнь, он так и не сможет полностью постичь предназначение хотя бы одной из ее ручек (не говоря уже обо всех). Однако мы знаем, что делает машина, потому что знаем, как ее создавали.
На этапе обучения языковой модели, которая по сути является алгоритмом для обработки текста, «скормили» огромный объем текстовых данных: всю Википедию, материалы, собранные со множества веб-сайтов, книги и так далее. Это позволило создать статистическую модель. Такая модель умеет определять вероятность следования одного слова за другим. Если я скажу «делу — время, потехе — …», вы можете догадаться с высокой степенью уверенности, что я закончу фразу словом «час» — так же и алгоритм. Это сжатое объяснение того, как работает языковая модель. Основываясь на «прочитанном», она с одинаковой легкостью и заканчивает за вас предложение, и предлагает наиболее вероятную последовательность слов в качестве ответа на заданный вопрос. В случае с ChatGPT процесс обучения включал в себя еще один этап более тонкой настройки — с ИИ беседовали реальные люди и отмечали ответы, которые казались им спорными (неточными, предвзятыми, расистскими и тому подобное). На основании их замечаний ChatGPT учился выдавать более корректные ответы.
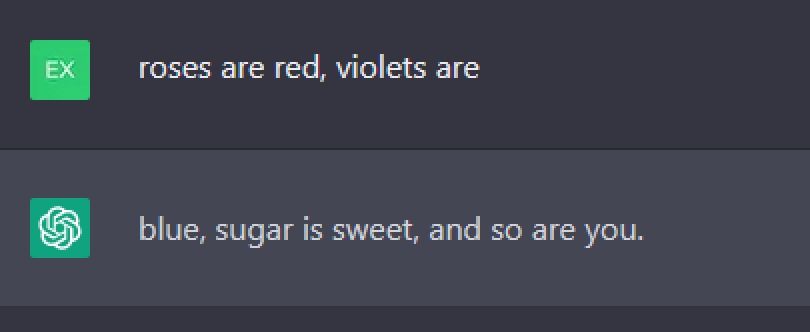
ИИ успешно заканчивает известную пословицу
Если понятие искусственного интеллекта не укладывается у вас в голове, расценивайте это как что-то вроде «математики» или «статистики»: цель этих моделей — прогнозирование. В диалоге с ChatGPT вам может начать казаться, что бот что-то знает, ведь он выдает подходящие по контексту и соответствующие предметной области ответы на впервые заданные вопросы. Но важно понимать, что искусственный интеллект даже не осознает значений слов, а лишь генерирует новый текст, который ему кажется естественным продолжением текущей «беседы». Это объясняет, почему ChatGPT может вести сложные философские дискуссии, но часто не справляется с базовой арифметикой: результат вычисления предсказать труднее, чем следующее слово в предложении.
К тому же у ChatGPT нет памяти: его обучение закончилось в 2021 году, и с тех пор модель не развивается. «Обновлениями» становятся новые модели (например, выход GPT-4 запланирован на 2024 год), обученные на свежих данных. На самом деле ChatGPT даже не помнит содержание беседы, которую вы с ним ведете: вся история текущего чата каждый раз обрабатывается заново вместе с новыми сообщениями, чтобы диалог выглядел более естественно.
Можно ли это назвать «интеллектом» (и сильно ли он отличается от человеческого интеллекта), станет предметом горячих философских споров в ближайшие годы.
Диффузионные модели
В основе таких инструментов для генерирования изображений, как Midjourney и DALL-E, лежат модели машинного обучения другого типа. Процедура их обучения, конечно, направлена на генерирование не текста, а изображений (по сути — наборов пикселей). Для создания изображения по текстовому описанию ИИ необходимо два навыка. Первый из них интуитивно очевиден — модели нужно научиться связывать слова с подходящими визуальными образами, поэтому на этапе обучения ей «скармливают» множество изображений с подписями. Как и в случае с ChatGPT, в итоге получается гигантская, непостижимая машина, которая очень хорошо умеет сопоставлять изображения с текстами. Машина понятия не имеет, как выглядит Брэд Питт, но, если ей показали достаточное количество его фотографий, она будет знать, что их объединяет. И если кто-то загрузит в нее новое фото Брэда Питта, модель его узнает и сообщит «да, это снова он».
Второй навык, который впечатляет меня больше, — это способность улучшать изображения. Для этого используется «диффузионная модель», обученная на четких изображениях, которые постепенно «зашумляются», пока не становятся нераспознаваемыми. Это позволяет обучить модель соотносить размытое изображение низкого качества с его аналогом в высоком разрешении — опять же на статистическом уровне — и воссоздавать более качественные изображения из нечетких оригиналов. На базе ИИ даже созданы специальные программы для удаления шумов и увеличения разрешения старых фотографий.

Пример снижения качества изображения (моей проверенной временем аватарки) для обучения диффузионной модели
Вместе описанные навыки позволяют модели синтезировать изображения. Она начинает со случайного шума и постепенно «улучшает» его, параллельно снабжая характеристиками, заданными в запросе пользователя (гораздо более подробное описание внутренних механизмов DALL-E можно найти здесь).
Споры не о том
Появление обсуждаемых в этой статье инструментов вызвало широкий общественный резонанс: не все приняли их с радостью. И это понятно, внезапное вторжение искусственного интеллекта в нашу жизнь может вызывать справедливые опасения. Однако, как мне кажется, большая часть дискуссий концентрируется сейчас совсем не на том, что по-настоящему важно. Но давайте сначала обсудим их, а потом перейдем к вопросам, которые, на мой взгляд, действительно имеют значение, когда речь идет об искусственном интеллекте.
DALL-E и Midjourney крадут у художников
Несколько раз я видел, что эти инструменты на базе ИИ описывают как программы, которые собирают «мозаику» из увиденных изображений, после чего применяют к ней фильтры, позволяющие имитировать стиль конкретного художника. Любой, кто заявляет такое, либо не разбирается в технических подробностях того, как создаются подобные модели, либо злонамеренно пытается ввести людей в заблуждение.
Как говорилось выше, модель совершенно неспособна извлекать ни изображения, ни даже простые формы из набора визуальных данных, на которых обучается. Все, что она может извлечь, — это их математические свойства.

То, с чего, по мнению людей, начинается работа DALL-E (слева), и то, с чего она начинается на самом деле (справа)
Да, на этапе обучения использовалось множество работ, защищенных авторским правом, — без явного согласия их создателей, и это, вероятно, можно обсуждать. Хотя стоит отметить, что человеческие живописцы учатся точно так же: студенты-художники копируют работы известных мастеров и черпают вдохновение в произведениях искусства, которые видят. А что такое вдохновение, как не способность ухватить суть произведения искусства в сочетании со стремлением открыть его заново?
Революционность DALL-E и Midjourney в том, что теоретически они могут вдохновляться картинами, созданными за всю историю человечества (и, вероятно, всеми, которые они же сами создают в настоящее время), но это отличие относится к масштабу, а не к сути процесса.

Убедительное свидетельство того, что Вольфганг Амадей Моцарт воровал у других авторов, пока обучался музыке
ИИ слишком облегчает работу художника
В этом случае критики обычно предполагают, что искусство должно быть тяжелой работой. Меня это всегда удивляло: ведь человек, который смотрит на произведение искусства, чаще всего не имеет представления о том, как много (или мало) усилий потребовалось для его создания. Этот спор не нов: с момента появления Photoshop прошло уже много лет, а некоторые все еще продолжают утверждать, что цифровое искусство нельзя считать настоящим. Сторонники противоположной позиции на это нередко возражают, что пользоваться Photoshop вообще-то тоже нужно уметь, но я считаю, что и они упускают главное. Много ли умения потребовалось Роберту Раушенбергу, чтобы рисовать белой краской на белом холсте? А сколько нужно практиковаться в игре на рояле, чтобы исполнить знаменитое произведение Джона Кейджа 4′33″?
Даже если принять умение за необходимый атрибут искусства, где провести черту? Сколько именно труда нужно вложить, чтобы искусство можно было назвать настоящим? Когда была изобретена фотография, Шарль Бодлер назвал ее «прибежищем неудавшихся художников, малоодаренных или слишком ленивых недоучек» и был не одинок в своей оценке. И оказался неправ.
ChatGPT помогает киберпреступникам
Некоторые СМИ стараются извлечь максимальную выгоду из ажиотажа вокруг ChatGPT и привлекают к себе внимание, вбрасывая скандальные инфоповоды. Как мы уже рассказывали, ChatGPT может помочь киберпреступникам написать фишинговое письмо или вредоносный код, однако и с тем и с другим преступники неплохо справляются и самостоятельно. Те, кто знает о существовании GitHub, понимают, что доступ к исходникам вредоносного ПО не является проблемой для злоумышленников, а беспокоиться об ускорении его разработки стоило еще после релиза Copilot.
Я понимаю, что глупо разоблачать шумиху в СМИ, вызванную не справедливыми опасениями, а погоней за мелочной выгодой. Но факт остается фактом: искусственный интеллект окажет огромное влияние на нашу жизнь, и существуют реальные проблемы, требующие решения. А споры вокруг надуманных вопросов только мешают их обсуждению.
Назад пути нет
Что бы вы ни думали об инструментах на базе ИИ, увидевших свет в 2022 году, знайте — их станет еще больше. Если вы считаете, что кто-то задумается о регулировании этой сферы до того, как станет поздно, то у меня для вас плохие новости: на данный момент политическим ответом на происходящее стало спонсирование исследований в области ИИ. Никто во власти не заинтересован в замедлении разработок.
Четвертая промышленная революция
Искусственный интеллект обеспечит (и, вероятно, уже обеспечил) повышение производительности. Насколько оно масштабно и как будет идти дальше — пока трудно предсказать. Если вы пишете тексты на основе других текстов, пора начинать волноваться. То же касается графических дизайнеров-фрилансеров: всегда будут клиенты, которым важна «частичка души автора», но большинство выберут более дешевый вариант. И это еще не все: реверс-инженерам, юристам, преподавателям, врачам и многим другим стоит ожидать серьезных изменений в своих профессиях.
Помните, что ChatGPT — чат-бот общего назначения. В ближайшие годы появятся специализированные модели, которые будут выполнять конкретные задачи намного лучше. Другими словами, ChatGPT не отнимет вашу работу сейчас, но высока вероятность, что в ближайшие пять лет появится новый ИИ-продукт, который сможет сделать это. И почти любая работа будет состоять в контролировании ИИ и корректировании результатов его работы.
Возможно, ИИ дойдет до предела возможностей и не будет больше развиваться — но после многих ошибок я выучил урок и больше не буду ставить против индустрии. Изменит ли искусственный интеллект мир так же сильно, как это сделал паровой двигатель? Будем надеяться, что нет, потому что резкие изменения в производственной сфере влекут за собой изменения в структуре общества, а это никогда не происходит бескровно.
Предвзятость ИИ и его собственники
О предвзятости инструментов на базе ИИ сказано уже достаточно, поэтому я не буду на этом останавливаться. Куда более интересно то, как OpenAI борется с этой предвзятостью. Как я уже упоминал, ChatGPT прошел этап контролируемого обучения, в ходе которого его пытались избавить от различных предубеждений. Задумка была отличной, однако в реальности этот процесс… привил чат-боту новые предрассудки. Условия этого этапа непрозрачны: кто те безвестные герои, решающие, какие ответы плохи? Низкооплачиваемые работники из стран третьего мира или достигшие просветления инженеры из Кремниевой долины? (Спойлер: правильный ответ — первый.)
Стоит также помнить, что все современные ИИ разработаны коммерческими компаниями, заинтересованными в первую очередь в получении прибыли. То, что они приносят какую-то условную пользу для человечества, — это скорее побочный результат. Если, конечно, вообще приносят. Ведь если даже такая несложная штука, как махинации с поисковой выдачей, может оказать значительное (и вполне измеримое) влияние на людей, то разнообразные помощники и советники с искусственным интеллектом тем более смогут незримо манипулировать мнениями пользователей.
Что теперь?
Вопрос о том, войдет ли искусственный интеллект в нашу жизнь, больше не стоит, поэтому следует хотя бы обсудить, как к этому подготовиться.
Прежде всего следует опасаться ситуаций, в которых ChatGPT (или его последующие модификации) будет принимать самостоятельные решения без человеческого контроля. Чат-бот умеет уверенно отвечать на вопросы, но это совершенно не означает, что он не умеет ошибаться. Тем не менее стремление сократить затраты и вывести людей из цикла принятия решений станет огромным соблазном.
Я также предсказываю, что в ближайшие десять лет основная часть контента в Сети (сначала текст и изображения, потом видео и игры) станет производиться с помощью искусственного интеллекта. При этом не думаю, что стоит рассчитывать на автоматические пометки о том, что контент произведен не человеком, — придется еще более критично относиться к тому, что мы читаем в Интернете, и пробираться через в десять раз большее количество белого шума, чем сейчас. Наибольшего опасения заслуживают специализированные модели, которые скоро появятся на рынке. Что произойдет, когда одна из компаний «Большой четверки» обучит модель на налоговом кодексе, а потом попросит ее найти в нем лазейки? А когда какой-нибудь высокопоставленный военный дорвется до диалогов с ChatGPT и решит: «дааа, я хочу что-то подобное в наших дронах»?
Искусственный интеллект возьмет на себя множество скучных задач, благодаря ему у людей появится масса новых возможностей и откроются совершенно новые формы искусства (да, это так). Но не все последствия внедрения ИИ будут столь радужными. Если не забывать об уроках истории, становится понятно, что искусственный интеллект с большой вероятностью сосредоточит еще больше власти в руках меньшинства и ускорит переход к технофеодализму. Он изменит способ организации труда и, может быть, даже повлияет на принципы взаимодействия человечества с накопленными им за всю историю знаниями. Хотим ли мы этого, уже совершенно не важно — ящик Пандоры открыт.
Источник: Лаборатория Касперского
03.03.2023


|
Как искусственный интеллект изменит нашу жизнь | Блог Касперского 2026 в Kaspersky-Security.ruМагазин антивирусных продуктов «Лаборатории Касперского», где можно быстро оформить заказ онлайн и купить надёжный антивирус Касперского: Kaspersky Standard, Kaspersky Plus, Kaspersky Premium, моментально получить ключ активации. Официальный партнер АО "Лаборатория Касперского". Получить всю необходимую информацию, обсудить вопросы покупки и оплаты антивирусов можно по телефону 8 (800) 350-59-04 или по адресу: info@kaspersky-security.ru |